Replicating Robbins and Davenport (2021) for the Philadelphia Promise Zone
2022-07-28
In the process of writing my job market paper, I ended up replicating a paper by two Rand Corporation econometricians who created a synthetic control package in R called microsynth. This package is made for meso and micro-level synthetic control specifications with many treated units. It is not clear to me that this method is as robust as synthdid from Arkhangelsky et al. (2021), so I ended up including it in the appendix of my JMP. In their demonstration of microsynth, Robbins and Davenport use the SeattleDMI dataset to study a drug market intervention at the block-level in Seattle. I do the same, but for the Philadelphia Promise Zone in West Philadelphia.
library(rgdal)
library(tidycensus)
library(dplyr)
library(lubridate)
library(tidyverse)
library(microsynth)
library(sf)
sf_use_s2(FALSE) #any kind of spatial intersection with large data will be too hard on your computer if you forge to use this option, trust me
########## MICROSYNTH Robbins et al. Methodology ########
crimez1 <- readRDS("crimez1.rds") #reading in my spatial dataset of crime
promise <- readOGR("C:/Users/Alex/Dropbox/PROJECTS/philly", layer="PhillyPlanning_Philadelphia_Promise_Zone" ) #load in promise zone## OGR data source with driver: ESRI Shapefile
## Source: "C:\Users\Alex\Dropbox\PROJECTS\philly", layer: "PhillyPlanning_Philadelphia_Promise_Zone"
## with 1 features
## It has 3 fieldsprm1 <- st_as_sf(promise) # as sf
prm2 <- st_transform(prm1, st_crs(crimez1)) #compatibility with crimez1
block <- readOGR(dsn ="C:/Users/Alex/Dropbox/PROJECTS/philly", layer ="a0937081-eccb-4da9-a95f-10395c086c932020329-1-lcydjk.c7huf")## OGR data source with driver: ESRI Shapefile
## Source: "C:\Users\Alex\Dropbox\PROJECTS\philly", layer: "a0937081-eccb-4da9-a95f-10395c086c932020329-1-lcydjk.c7huf"
## with 18872 features
## It has 18 fieldsblock1 <- st_as_sf(block) #READING IN BLOCKS and making them sf
block1$id <- as.numeric(sub("42101","",block1$GEOID10))
block2 <- st_transform(block1, st_crs(crimez1)) #making it compatible with crimez1
vars10 <- c("P001001", "P006003", "P011002", "P012006", "P012007", "P012008",
"P012009", "H018003", "H018013","H004004","H003003") #defining variables for census request
pa <- get_decennial(geography = "block", variables = vars10, year = 2010, state = "PA", geometry = FALSE, output="wide")
philblock <- subset(pa, grepl("Philadelphia", pa$NAME,fixed=TRUE)) #census block info for just philadelphia
philblock$id <- as.numeric(sub("42101","",philblock$GEOID))
blockintersection <- st_intersection(x = block2, y = crimez1)## Warning: attribute variables are assumed to be spatially constant throughout all
## geometriesblockintersection$year <- as.numeric(year(blockintersection$dispatch_date)) #get a year var
blockintersection$violent <- ifelse(blockintersection$text_general_code %in% c("Robbery Firearm","Other Assaults", "Aggravated Assault No Firearm","Aggravated Assault Firearm","Rape","Robbery No Firearm", "Homicide - Criminal", "Homicide - Gross Negligence", "Arson", "Other Sex Offenses (Not Commercialized)","Homicide - Justifiable"), 1, 0)
blockintersection$nonviolent <- ifelse(blockintersection$text_general_code %in% c("Robbery Firearm","Other Assaults", "Aggravated Assault No Firearm","Aggravated Assault Firearm","Rape","Robbery No Firearm", "Homicide - Criminal", "Homicide - Gross Negligence", "Arson", "Other Sex Offenses (Not Commercialized)","Homicide - Justifiable", "Liquor Law Violations", "Gambling Violation", "Forgery and Counterfeiting", "Embezzlement", "Public Drunkenness", "Forgery and Counterfeiting", "Fraud", "DRIVING UNDER THE INFLUENCE", "Recovered Stolen Motor Vehicle") , 0, 1)
blockintersection$property <- ifelse(blockintersection$text_general_code %in% c("Theft from Vehicle","Motor Vehicle Theft", "Thefts","Burglary Residential", "Burglary Non-Residential", "Receiving Stolen Property"), 1, 0)
blockintersection$unrelated <- ifelse(blockintersection$text_general_code %in% c("Embezzlement", "Fraud", "Forgery and Counterfeiting","Gambling Violation"), 1, 0)
blockintersection$homicide <- ifelse(blockintersection$text_general_code %in% c("Homicide - Criminal", "Homicide - Justifiable"), 1,0)
blockintersection$assault <- ifelse(blockintersection$text_general_code %in% c("Other Assaults"), 1,0)
blockintersection$aggassault <- ifelse(blockintersection$text_general_code %in% c("Aggravated Assault No Firearm"), 1,0)
blockintersection$aggassaultfirearm <- ifelse(blockintersection$text_general_code %in% c("Aggravated Assault Firearm"), 1,0)
blockintersection$rape<- ifelse(blockintersection$text_general_code %in% c("Rape"), 1,0)
blockintersection$robbery<- ifelse(blockintersection$text_general_code %in% c("Robbery No Firearm"), 1,0)
blockintersection$robfirearm<- ifelse(blockintersection$text_general_code %in% c("Robbery Firearm"), 1,0)
blockintersection$arson<- ifelse(blockintersection$text_general_code %in% c("Arson"), 1,0)
blockintersection$othersex<- ifelse(blockintersection$text_general_code %in% c("Other Sex Offenses (Not Commercialized)"), 1,0)
blockintersection <- subset(blockintersection, blockintersection$year >2009 & blockintersection$year <2020)
blockintersection$zone <- st_within(blockintersection, prm2) %>% lengths > 0 #crime committed in the zone
#saveRDS(blockintersection, "blockintersection.rds")######LOAD blockintersection#####
#readRDS("blockintersection.rds") -> blockintersection
aggblock <-aggregate(blockintersection[,c("violent", "nonviolent", "property", "unrelated","homicide","assault","aggassault", "aggassaultfirearm","rape","robbery","robfirearm","arson", "othersex","zone")], list(blockintersection$id, floor_date(blockintersection$dispatch_date , "quarter")), sum)
aggblock <- aggblock %>%
rename(
# gisjoin=Group.1
id = Group.1,
date = Group.2
)
aggblock <- aggblock %>% complete(id, date) #complete the cases for blocks that don't have a crime in a quarter
aggblock[is.na(aggblock)] <- 0 #turn NAs into 0s
aggblock$year <- year(aggblock$date)
aggblock$post <- ifelse(aggblock$year > 2013,1,0)
aggblock$zone <- ifelse(aggblock$zone>0, 1,0)
aggblock$treat <- aggblock$zone*aggblock$post
aggblock <- merge(philblock, aggblock, by=c("id")) #merging decennial blocks with quarterly crime data
aggblock$male15to21 <- aggblock$P012006+aggblock$P012007+aggblock$P012008+aggblock$P012009
aggblock <- aggblock %>% arrange(id) #arrange in order
aggblock$time <- rep(seq(from=1,to=40, length.out=40), 16974) #making time sequence variable (16974 blocks)
#saveRDS(aggblock, "aggblock.rds")#########LOAD aggblock##########
#readRDS("aggblock.rds") -> aggblock
cov.var <- c("P001001","P006003","P011002","male15to21","H018003","H018013","H004004","H003003")
match.out <- c("violent", "assault","aggassault", "aggassaultfirearm","robbery","robfirearm","homicide","rape","othersex","arson", "nonviolent","property")
philblocksynth <- microsynth(aggblock, #synthetic control without the empty blocks
idvar="id", timevar="time", intvar="treat",
start.pre=1, end.pre=17, end.post=40,
#authors recommend starting period of treatment as final period if you do not believe treatment uptake will be immediate
match.out=match.out, match.covar=cov.var,
result.var=match.out, omnibus.var=match.out,
test="lower", perm=FALSE, jack=FALSE, #I use permutation and jackknife for inference in my paper, but exclude them here for easy knitting
n.cores = min(parallel::detectCores(), 6)) #using 6 of my 8 cores for faster processing## Warning in classes[i] <- class(data[, i]): number of items to replace is not a
## multiple of replacement lengthphilblocksynth #view the results## microsynth object
##
## Scope:
## Units: Total: 16974 Treated: 460 Untreated: 16514
## Study Period(s): Pre-period: 1 - 17 Post-period: 18 - 40
## Constraints: Exact Match: 213 Minimized Distance: 0
## Time-variant outcomes:
## Exact Match: violent, assault, aggassault, aggassaultfirearm, robbery, robfirearm, homicide, rape, othersex, arson, nonviolent, property (12)
## Minimized Distance: (0)
## Time-invariant covariates:
## Exact Match: P001001, P006003, P011002, male15to21, H018003, H018013, H004004, H003003 (8)
## Minimized Distance: (0)
##
## Results:
## end.post = 40
## Trt Con Pct.Chng Linear.pVal Linear.Lower Linear.Upper
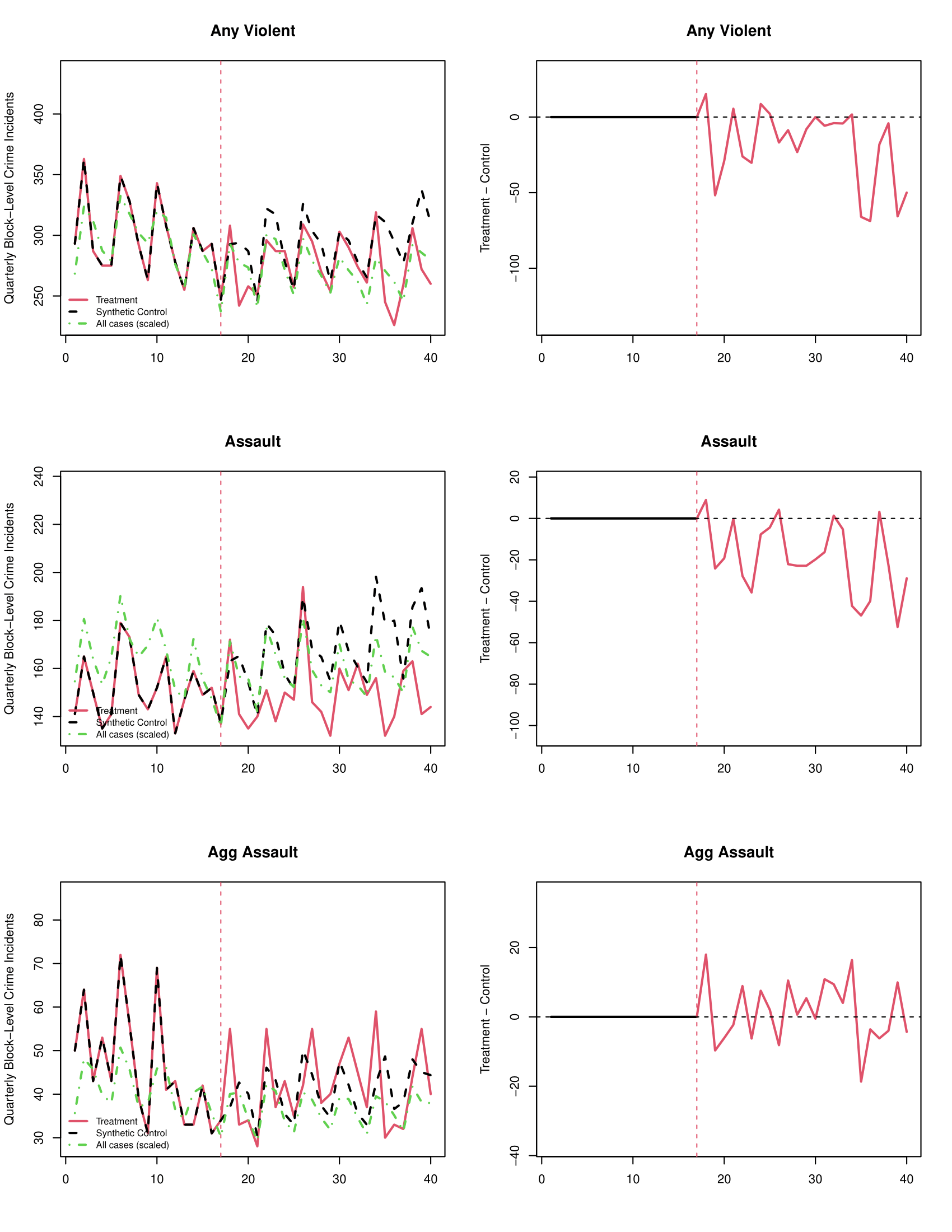
## violent 6329 6776.22 -6.6% 0.0003 -9.7% -3.4%
## assault 3445 3888.71 -11.4% 0.0000 -15.0% -7.7%
## aggassault 970 936.21 3.6% 0.8056 -3.1% 10.8%
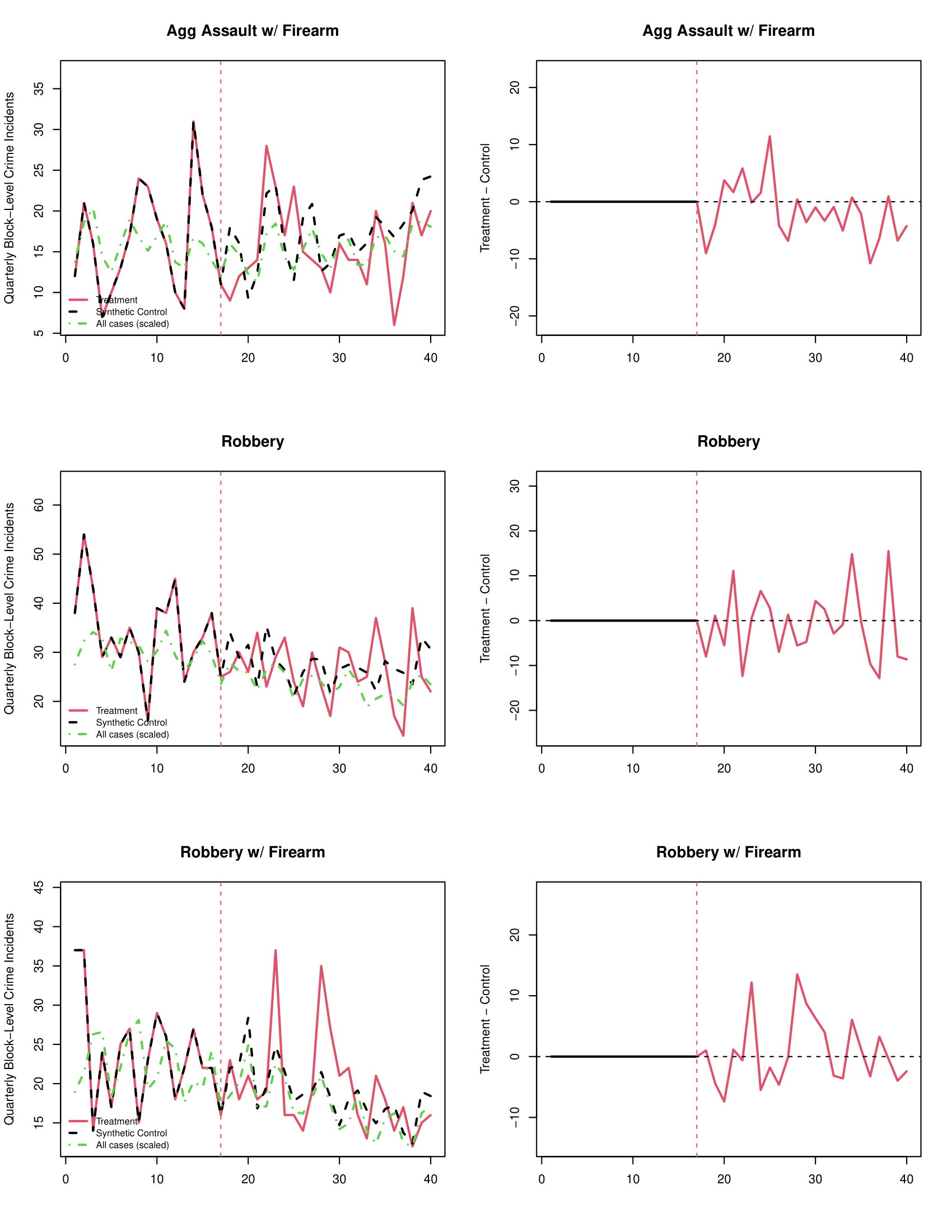
## aggassaultfirearm 358 400.13 -10.5% 0.0625 -21.0% 1.3%
## robbery 605 630.46 -4.0% 0.1916 -11.3% 3.8%
## robfirearm 448 431.71 3.8% 0.7528 -5.0% 13.3%
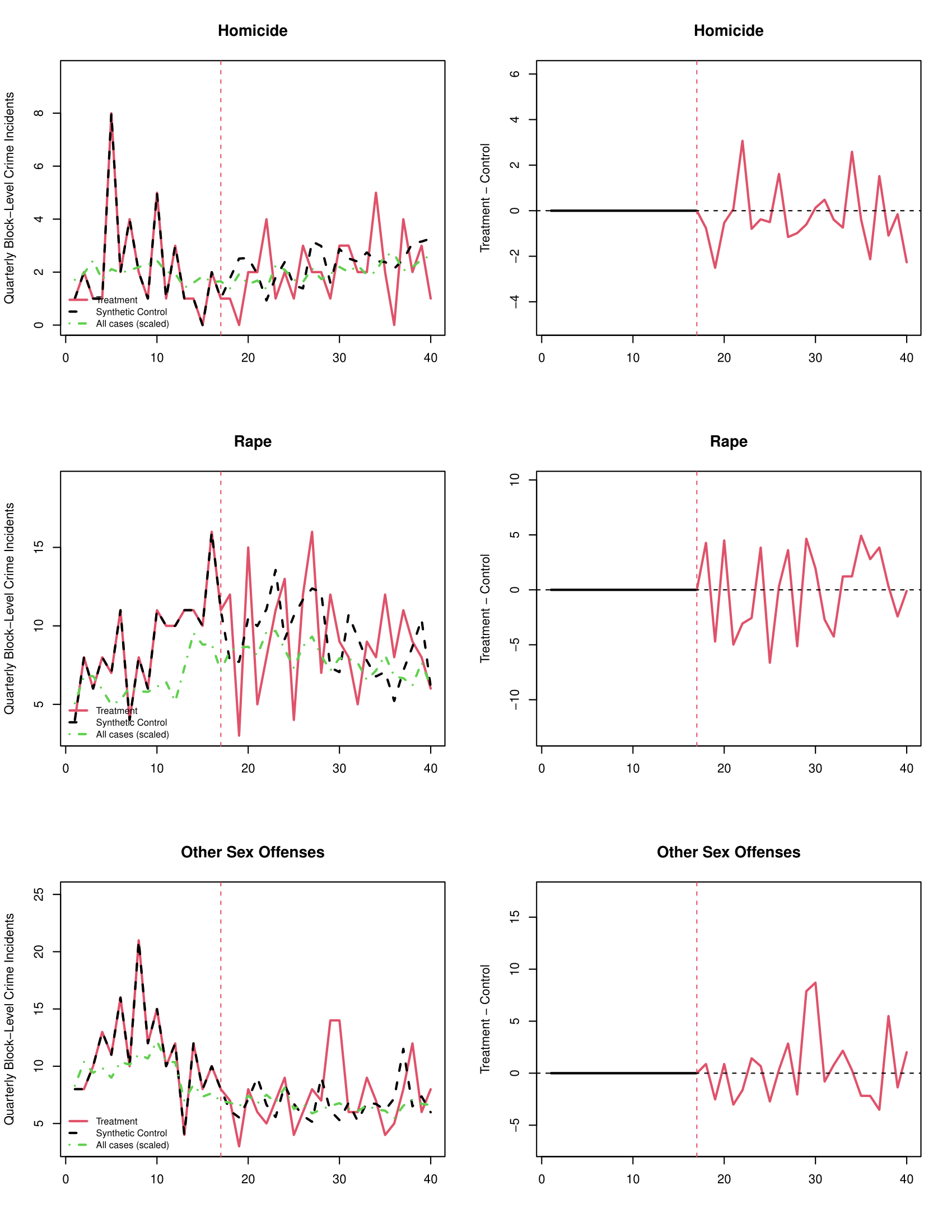
## homicide 48 53.92 -11.0% 0.2208 -31.3% 15.4%
## rape 211 210.09 0.4% 0.5214 -12.1% 14.7%
## othersex 169 156.62 7.9% 0.7776 -8.2% 26.8%
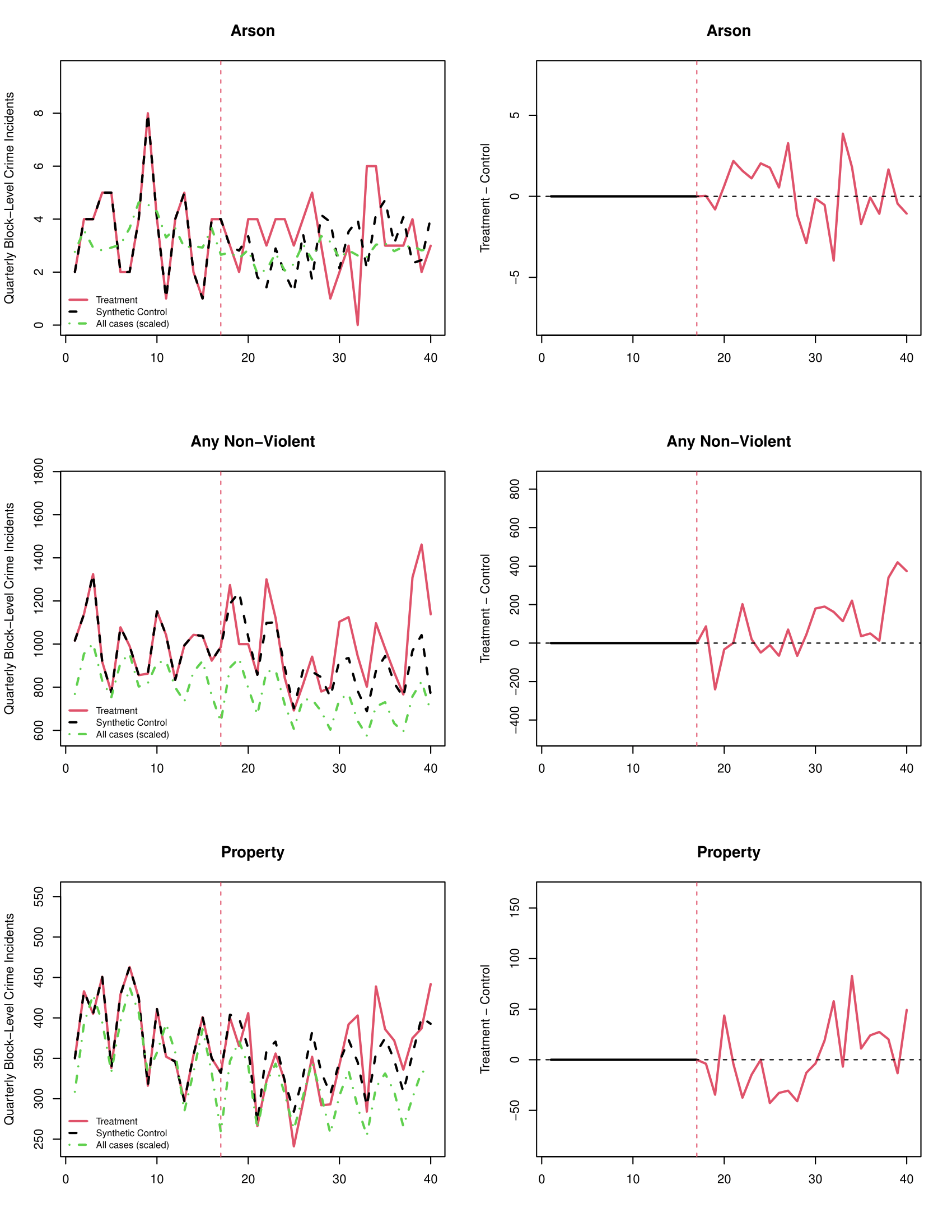
## arson 75 68.39 9.7% 0.7590 -11.0% 35.2%
## nonviolent 23018 20961.98 9.8% 0.9992 4.6% 15.3%
## property 8068 8010.85 0.7% 0.6261 -2.9% 4.4%
## Omnibus -- -- -- 0.1050 -- --par(mfrow=c(12,2)) #setting up a grid for 12 rows of 2 plots each
plot_microsynth(philblocksynth, ylab.tc=c("Quarterly Block-Level Crime Incidents"),
main.tc=c("Any Violent","Assault","Agg Assault","Agg Assault w/ Firearm","Robbery","Robbery w/ Firearm","Homicide","Rape","Other Sex Offenses","Arson", "Any Non-Violent","Property"),
main.diff=c("Any Violent","Assault","Agg Assault","Agg Assault w/ Firearm","Robbery","Robbery w/ Firearm","Homicide","Rape","Other Sex Offenses","Arson", "Any Non-Violent","Property"), sep=FALSE,width=8.5 ) #plotting all twelve